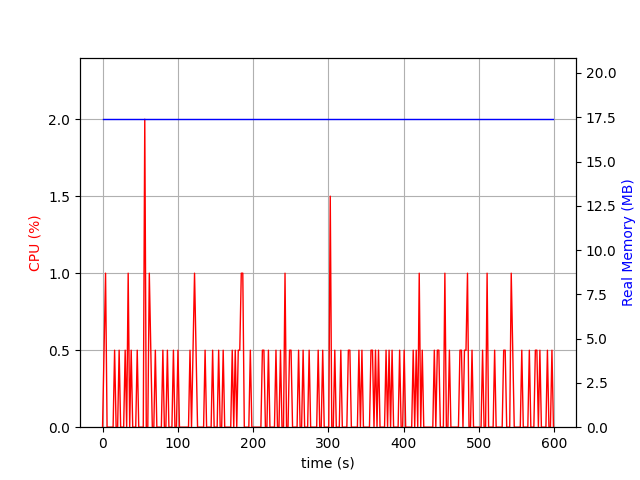
I did block the ULAs for a short while, but then switched to disabling the secondary port in order to allow it to still use the ULAs in case those were better routes. Doing that seems to at least not fill up the path structure and prevent the constant new path discovery I was seeing. I’m now getting expected CPU usage with a sample of less than 2% CPU usage over a 10 minutes (see picture).
I was wondering where the 3rd port was coming from, so that makes sense it’s coming from UPnP. Though for my 2 peers in question on this thread, they are on my home network and do utilize UPnP. Which does raise the question of expired and renewed UPnP ports. I would assume that as a UPnP mapped port expires a new one will be issued. Which in turn will add to the number of paths, but remove old ones as they expire. I assume ZeroTier deals with those already.
I do have 2 Cloud VMs that I could disable port mapping on. Though I don’t think I’ve been able to get a Direct P2P connection on my Cloud VMs (Azure and Oracle) even though I feel like I’m setting everything up correctly in config and opening UPD port 9993. I’d love to somehow confirm/deny that too.
For the cloud nodes, check zerotier-cli peers for “direct” or “relay” .
You kind of need to allow all outgoing udp, other nodes are behind NAT and get mapped to random ports.
I’m not sure what kind of options you have for the azure or oracle firewall.
If it’s iptables you can use -A OUTPUT -m owner --uid-owner zerotier-one -j ACCEPT to allow just zerotier-one to send anything.
I’m also having this high CPU usage issue, I reboot my Pi 4 or restart the zerotier-one service and it goes away for like 6 hours ish.
Would disabling IPv6 help perhaps? I am getting “200 peers”.
I’ve resorted to creating a cron job that restarts zerotier at 07:45am every morning, I suspect i’ll needa run this a few more times later as the day goes on and it starts eating all my CPU.
Updated my Almalinux servers and 2 x Synology DSM7 to latest and now they also have the issue, 100% CPU load on Zerotier after a few pings. Rolled back the Synologys to 1.8.10 and all OK.
Our backups and some internal services run over ZT and although I love to keep running ZT, I can’t support this much longer.
How do I re-install ZT 1.18.10 on Centos / Almalinux with yum?
thanks
Thanks, I found that also yesterday.
Had to remove also the repo as it updated with the same speed last night to 1.10.3.
Now running on 1.8.10 and seems fine again.
Even after disabling the secondary port, this is still an issue. Not only on my RaspberryPi 4, but also on other peers on my home network (both Mac Book Pros). I’m yet again getting constant 100% CPU usage on my Pi4, and now getting ~33% constant CPU usage on my MBPs.
I don’t really want to disable IPv6 on my network, or blocking ZeroTier traffic on my IPv6 routes. Is a fix for this being worked on? Is there any timeline for a fix?
I was looking into this further and for one of my local peers (from MBP to Pi4) the paths were full again. So I looked at one IPv6/port combination open on the Pi4 connecting from the MBP. This one IPv6/port combo had 27 combinations because it had 27 different local sockets on the MBP. Why is there so many different local sockets? Are they building up over time?
I’m also not sure what port this is (which is 34029) because it’s not the standard 9993 port. Yet, at the same time this IPv6 only has 2 paths for the standard 9993 port. I suppose that may be because the path structure is full and the other paths for 9993 couldn’t fit. But another IPv6 address has 27 combinations for the 9993 port but only 3 for 34029.
Doesn’t seem to be too big, disabling IPv6 seems to allow it to run longer before getting choppy on the streaming but I can’t be sure.
My scenario is using TVHeadend remotely to stream video.
Main issue I’m having is after a random number of hours streaming video over zerotier it seems to become unresponsive until I restart the zerotier-one service on the remote/tvheadend server at which point it becomes responsive and flawless again (I can’t determine what’s causing it exactly as bandwidth certainly isn’t an issue, but it’s definitely zerotier related as every time I restart the zerotier-one service performance returns).
If I can provide logs or anything for you let me know and I’d be happy to assist, because other than this issue Zerotier is pretty magic in terms of ease (You’ve a good thing going here).
We are considering bumping the max paths again but we want to fully understand why people are finding themselves in this situation before we take the easy way out. Can you tell me more about the assigned addresses for your local node with ~1500 paths and one of the remote peers with 64+ paths?
it had 27 different local sockets on the MBP. Why is there so many different local sockets?
This is due to how ZeroTier enumerates paths, it’ll bind to up to three ports (one 9993, two random for helping with NAT) for each interface. One explanation could be if you had (3 interfaces on machine A) * (3 ports on machine A) * (1 interface on machine B) * (3 ports on machine B) = 27
The other address only showing two paths could be for the reason you cite: the path structure is already full and can’t learn the other 25 combinations (or such.)
Is a fix for this being worked on? Is there any timeline for a fix?
Yes. I’m considering options currently. It’ll likely be a small fix but I want to make sure it makes sense before I bump that number again. No timeline, but I’d like this fixed ASAP so it shouldn’t be too long.
The reason people find themselves with an exploding number of paths is that ZeroTier builds the cross product {local underlay addresses} x {local ports} x {remote addresses} x {remote ports} and takes a while to forget old addresses. It’s common for docked laptops to have at least two networks interfaces (Wi-Fi and Ethernet) up and configured (with useable default routes offered via DHCPv4 and IPv6 SLAAC router advertisements on both). Even with good stable network connections client operating systems will add a temporary privacy IPv6 host address about every 5 minutes keeping them around as long as there is at least on socket still using them. This can easily get you 10 local IP addresses per interface times 3 ports per side for 10 * 2 * 3 = 60 potential combination per side. If you have the same on both sides there are 60 * 60 = 3600 potential combinations. Now add a moderate amount of network brokenness e.g. frequent Wi-Fi reconnects/roaming or maybe “energy efficient” Ethernet NICs reporting each link wakeup as quick link-state up/down/up transitions, or nested (CG)NAT networks and you can go through even more addresses in the minutes to hours the ZeroTier control plane can take to garbage collect old address and port combinations. If a node insists on roaming periodically between a few (wireless) networks it can keep all of them in the control plane. Just cycling through all combinations isn’t feasible and the 1.10.3 release has major performance regressions (at least on macOS) to a degree that I had to downgrade all my ~50 nodes to at most 1.10.2 because otherwise certain combinations of hosts were effectively cut of from each other while wasting up to 40% of an Apple M1 Max CPU core. You’re calling getifaddrs() far too often. I shared the call stack profile traces and dump files I captured with @zt-travis along with a few other observations via PM.
Thank you for this. We can consider forgetting paths more quickly as part of a broader solution. And I’ll see what we can do about the spamming of getifaddrs.
The ULA prefix is fc00::/7. Filtering fd00::/8 would block only the upper half of it. Trailing zeroes inside a 16 bit group can’t written like that. fd:: is short for 00fd:: and doesn’t make sense as network address for anything shorter than a /16 prefix. Your intention is clear, but such tiny notational mistakes can confuse those not yet familiar with IPv6. Filtering the wrong prefix won’t tell anyone if blocking ULA reduces the problem. Sorry for the pedantic (and annoying) comment.
In our testing this limits the number of paths significantly and should prevent the issues mentioned above. Please let us know if you continue to have problems.