Hi! I recently made the transition from Tailscale to ZeroTier, and I’m running into some issues:
I have 3 nodes:
10.147.20.237 (my laptop, w10)
10.147.20.223 (a server running debian, let’s call it A)
10.147.20.63 (a server running ubuntu, let’s call it B)
From my laptop, I can:
ping A, curl services in A
ping B, curl of services in B give this error: curl: (28) Failed to connect to 10.147.20.63 port 8080 after 21043 ms: Couldn't connect to server
From A, I can:
ping my laptop, curl services in my laptop
ping B, curl of services in B, give this error: curl: (7) Failed to connect to 10.147.20.63 port 8080: No route to host
From B, I can:
ping my laptop, curl services in my laptop
ping A, curl services in A
It’s clear the problem lies in B somehow. I don’t have any firewall rule in both cloud providers and both servers are blocked for all incoming ports.
I thought that maybe the problem could be the service I was testing, so I also performed that test using python -m http.server in different ports.
Today I also tried to access a server set up in Python like that in another PC (w10) and couldn’t connect to it (but I attributed that to maybe some Windows firewall rule, didn’t give it much thought), but I’m not sure if that’s related.
In Tailscale I had all that working without issues, I just had open an UDP port in those servers for it to work “better”, but had no issues with Windows firewalls or anything like that, so that makes me think about crossing that out, but I’m not sure.
Is there something I’m missing? I’m kinda lost, does anyone have any idea of what could be the issue?
This is most likely a host firewall on your B node. It can talk to anything provided it initialized the traffic, but can’t talk if it didn’t. This is typical stateful firewall behavior… You can disable it entirely for testing and see if your tests succeed. If they do, just modify that firewall to allow the traffic.
If that wasn’t the issue, it’s possible the service(s) you’re trying to use on it are strictly bound to a non-ZT interface. You can verify that with “netstat -ln”. If it says 0.0.0.0:8080:, it means it’s listening on all IPs on the host on port 8080: If it says :8080, then the service is bound to just that IP.
This won’t impact the issue you’re posting about, but it’s good info. Once ZeroTier is up, whatever traffic you send over it will be transparent to the CSP/ISPs that it traverses, but just like Tailscale, you may be able to make it work “better” if needed. You can run “zerotier-cli listpeers” on all of your nodes and make sure that traffic between your nodes are not listed as RELAY. ZeroTier is pretty good about finding a way to make a direct connection, but if it does show RELAY, it wasn’t able to and your traffic is using ZeroTier’s infrastructure to route between your nodes.
The thing is, I don’t even have the firewall enabled in this machine. It does have ufw installed, but it came disabled. I even changed the DEFAULT_INPUT_POLICY in /etc/default/ufw to “ACCEPT” and enabled the firewall, but got the same result.
The netstat -ln command showed me this: tcp6 0 0 :::8080 :::* LISTEN
This looks like it’s listening in ipv6 (?), do you know if this is an issue somehow?
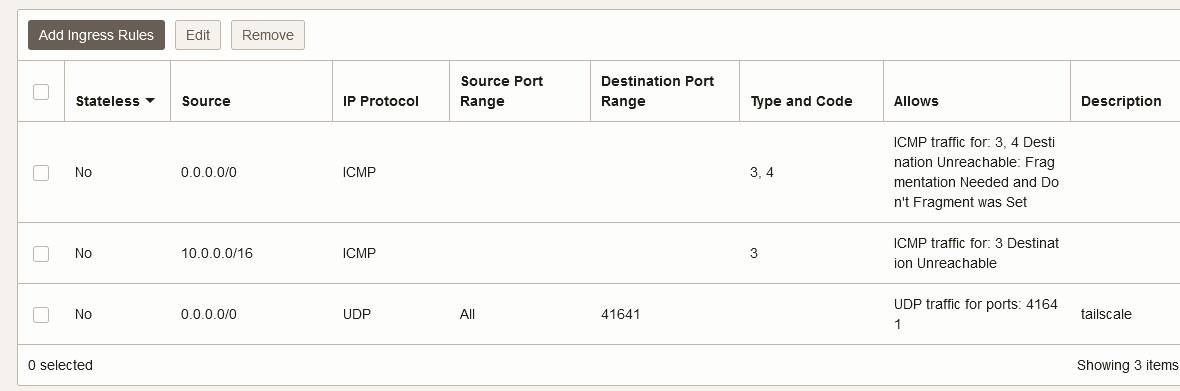
Regarding the network rules, those are all the ingress rules I have in Oracle Cloud:
About make ZeroTier run “better”, is there any ports I should forward to make it so? I didn’t see anything listed as RELAY, but if there was, how can I make this not happen?
That could be your issue if it’s only listening on IPv6. You can run the netstat command with a -4 or -6 switch as well to further scope the listening ports:
netstat -ln4
netstat -ln6
Here’s a couple more things that might be helpful:
Run nmap from your laptop/node-A to node-B on port 8080 and see what it reports.
Run a tcpdump on Node B while you’re running your curl to it. This could give you an indication on what’s happening at the packet level.
The primary port that ZeroTier uses for communication is UDP/9993. You can forward and allow that if you wanted.
I’m a bit lost on where to go. netstat -ln4 doesn’t show the port I’m interested on. netstat -ln6 on the other hand, does show it: tcp6 0 0 :::8080 :::* LISTEN
Before, I was using sudo ss -tunlp to check, and the output on it is: tcp LISTEN 0 4096 *:8080 *:* users:(("faasd",pid=58921,fd=9))
I tried the tcpdump, but no way in hell I can interpret that one.
Thinking about this being a IPV6 issue, I set up a proxy in nginx to make the redirection like that:
This does show up in netstat as listening to IPV6 and IPV4, and the redirection does work (tested with curl localhost:8085), but again, outside this server, I can’t reach it.
From node A to B, I performed this nmap:
> nmap -Pn -p 8085 10.147.20.63
Starting Nmap 7.80 ( https://nmap.org ) at 2023-11-12 16:15 UTC
Nmap scan report for 10.147.20.63
Host is up (0.20s latency).
PORT STATE SERVICE
8085/tcp filtered unknown
Nmap done: 1 IP address (1 host up) scanned in 0.24 seconds
> nmap -Pn -p 8080 10.147.20.63
Starting Nmap 7.80 ( https://nmap.org ) at 2023-11-12 16:15 UTC
Nmap scan report for 10.147.20.63
Host is up (0.20s latency).
PORT STATE SERVICE
8080/tcp filtered http-proxy
Nmap done: 1 IP address (1 host up) scanned in 0.24 seconds
I also forwarded the UDP 9993 port and tried to check the ZeroTier RFC4193 (/128 for each device) in the ZeroTier Network page, but this didn’t help at all.
I’m trying to run faasd and the output is net.ipv6.bindv6only = 0. What makes me not think of an application issue is because this worked before with Tailscale. I have no idea what kind of magic they did, but I could access this application outside node B.
As long as the host isn’t listening on that port, you’ll never be able to build a socket to it.
Is tailscale still installed? If you bring it back up, do you now see it listening on 100.x.x.x on port 8080? If so, it could indicate something is pointing to that IP specifically in a conf or hosts file.
Have you rebooted the host running faasd since troubleshooting all of this? A reboot also might cause the IP to get rebound.
If it was still only listening on IPv6 when you were using tailscale, maybe tailscale is doing some native 4-to-6 translation. You can try disabling IPv6 and see if that forces it to bind to an IPv4 address.
I’m not familiar with faasd, but it seems to have a pretty robust logging capability. There might be something in there indicating an issue.