SELinux issue causing segmentation fault on RedHat based distributions: Fix with the following command: sudo setsebool -P mmap_low_allowed 1
Reports of segfault on some Debian based distributions, though thus far we’ve been unable to reproduce these locally.
segmentation fault running in Docker container: Fix by running with --cap-add=CAP_SYS_RAWIO
ZeroTier won’t bind to 203.0.0.0/24. Fix already in on GitHub in the dev branch
segmentation fault running in LXC.
On some Windows machines, ZeroTier appears to require a reboot after upgrading from a previous version. Can also be triggered by leaving/joining networks repeatedly. Still investigating.
Not working on older versions of macOS (macOS 11 Big Sur works fine)
1.6.1 has now been released
Fixed a bug that caused IP addresses in the 203.0.0.0/8 block to be miscategorized as not being in global scope.
Changed Linux builds to fix segfaults, LXC and SELinux issues.
Fixed unaligned memory access that caused crash on FreeBSD systems on the ARM architecture.
Merged CLI options for controlling bonded devices into the beta multipath code.
Fixed issue that could cause a network feedback loop on Windows and possibly FreeBSD.
Updated Windows driver with Microsoft cross-signing to fix issues on some Windows systems.
I’m also having segmentation faults running zerotier-cli on an unprivileged Centos 8 LXC container running under Proxmox. Before I saw this thread, I thought I’d poke at the source for my own understanding of what exactly is segfaulting.
I don’t know if this means anything but if I compile from the source on GitHub, I don’t get any segfaults with the zerotier-one binary that gets built. I tried the tagged 1.6.0 and latest master. I even tried latest dev branch which is a moving target as commits are occurring simultaneously to my testing.
I was experimenting with moons in 1.4.6 in this unprivileged LXC machine. Now the machine seems to be running as a 1.6.0 moon if I compile the binary myself.
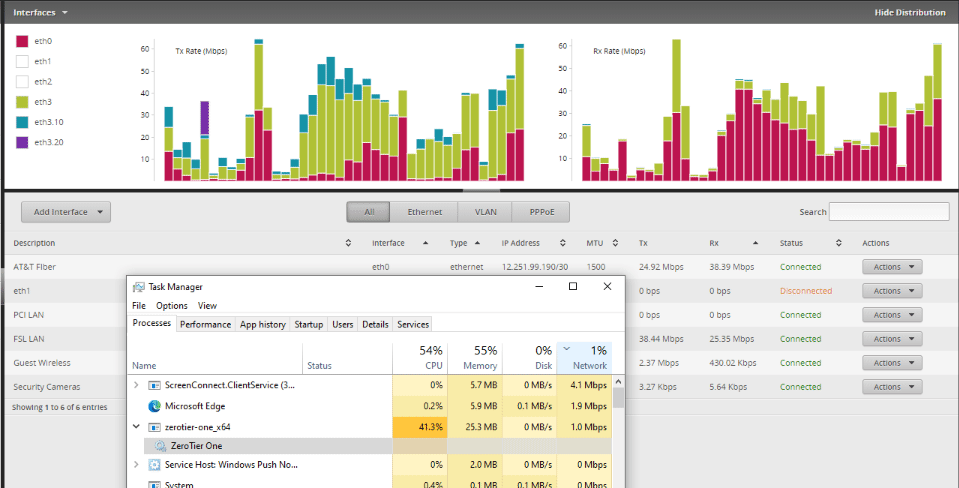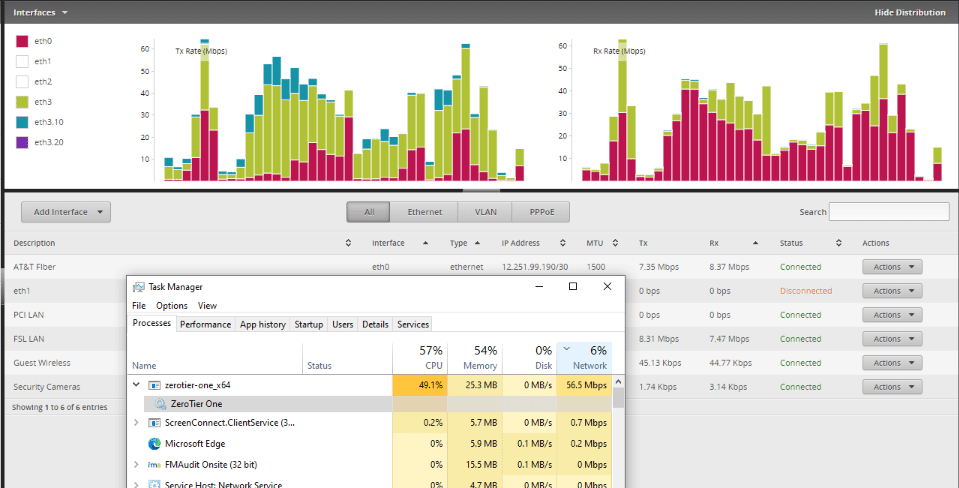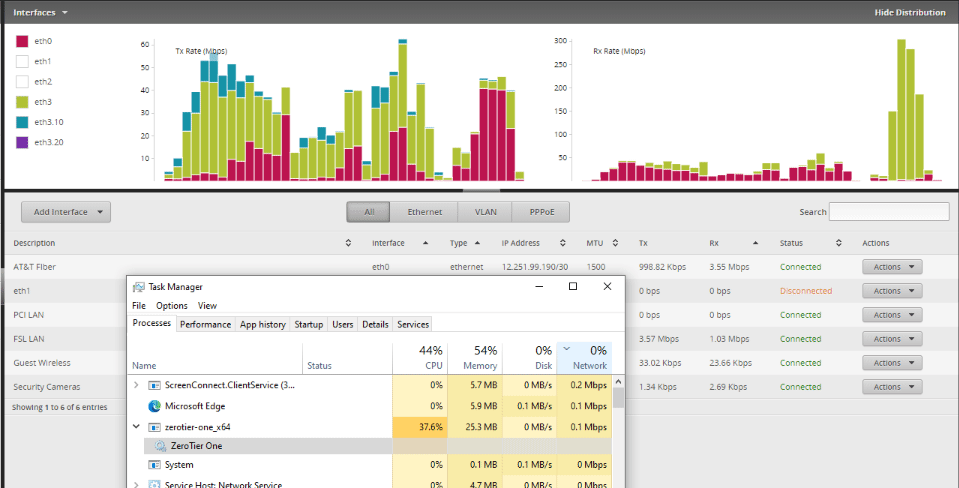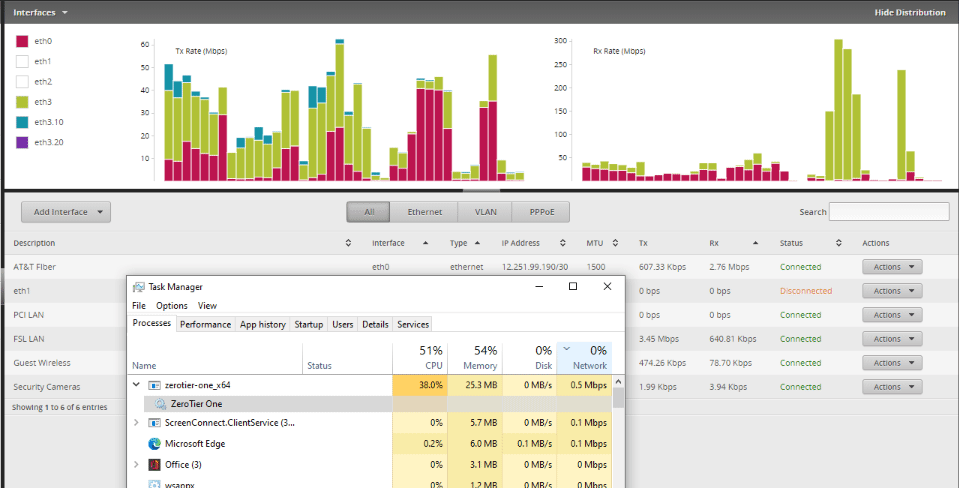
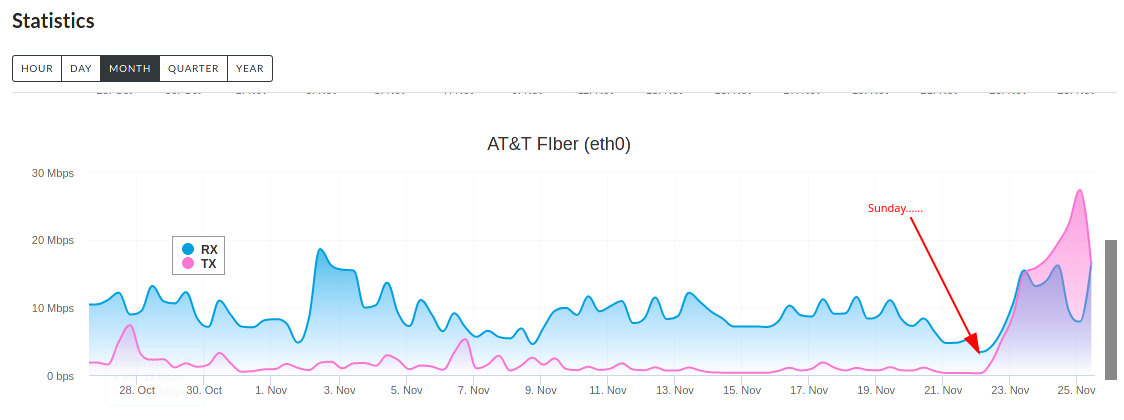
All of the Windows machines at one site updated 1.6.0 via chocolately after it was pushed to that service on the 22nd.
Immediately, my network connectivity went to crap. The site has a 50/50 non-shared fiber from AT&T and the upstream was suddenly maxed out.
After much troublshooting over the last 2 days, the commonality of ZeroTier as discovered. I globally stopped the ZeroTeir service and the network immediately recovered to normal state.
The ZeroTier service on Linux is not apparently affected. Those devices are online and not causing issues.
Well that’s a new one for sure. Definitely not something I’m able to reproduce over here as of yet. Anything nonstandard about your network configuration? Does rebooting help at all?
# Whitelist only IPv4 (/ARP) and IPv6 traffic and allow only ZeroTier-assigned IP addresses
drop # drop cannot be overridden by capabilities
not ethertype ipv4 # frame is not ipv4
and not ethertype arp # AND is not ARP
and not ethertype ipv6 # AND is not ipv6
# or not chr ipauth # OR IP addresses are not authenticated (1.2.0+ only!)
;
# Allow SSH and RDP by allowing all TCP packets (including SYN/!ACK) to these ports
accept
ipprotocol tcp
and dport 22 or dport 3389
;
# Create a tag for which department someone is in
tag department
id 1000 # arbitrary, but must be unique
enum 100 servers # has no meaning to filter, but used in UI to offer a selection
enum 200 sales
enum 300 hr
;
# Allow Windows CIFS and netbios between computers in the same department using a tag
accept
ipprotocol tcp
and tdiff department 0 # difference between department tags is 0, meaning they match
and dport 139 or dport 445
;
# Drop TCP SYN,!ACK packets (new connections) not explicitly whitelisted above
break # break can be overridden by a capability
chr tcp_syn # TCP SYN (TCP flags will never match non-TCP packets)
and not chr tcp_ack # AND not TCP ACK
;
# Accept other packets
accept;
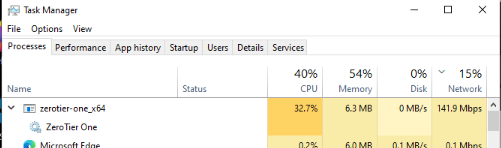
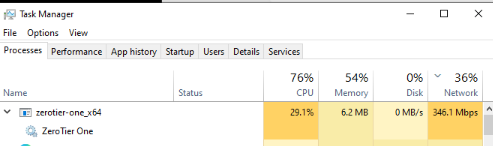
OK. I was able to get that behavior of ZT pushing a ton of bandwidth for a minute right after it started up in the debugger. It did settle down a lot after that, but still seems to use more bandwidth than I’d expect on otherwise idle networks. Still trying to figure out the cause.
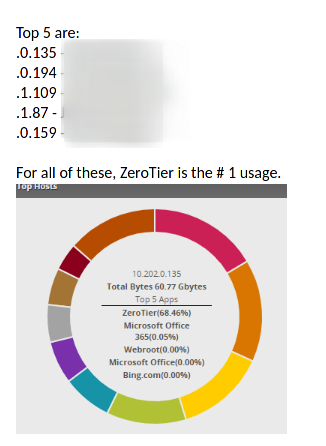
With ~25 of my devices on the one network, a burst like that can be a lot of traffic.
If it is only a burst, then base don my experience, I would expect that it will repeat at some interval.
It is 100% certain that ZT was what killed my network. I’m turning the service back on for a couple of remote users now. WIll keep an eye on things.
Sunday is when it was released to chocolatey. Look at my network history. The graph only updates every 8 hours on the month view. so it will not show normal for a while now that I have shut down the service globally.